
Excel is one of the most powerful tools for data analysis, but it has limits. When datasets grow into millions of rows, when reports need to run automatically, or when analyses require machine learning, Excel alone starts to show its age. Python fills many of these gaps. Python integration has transformed Excel from a traditional spreadsheet tool into a more powerful data analysis platform. With Python available directly inside Excel, analysts can now perform advanced calculations, build predictive models, and generate sophisticated visualizations without leaving their workbook.
In this tutorial, we will show five Python libraries for advanced Excel data analysis that every pro should use. These libraries allow you to perform advanced data manipulation, visualization, and machine learning directly within Excel.
1. Pandas – The Core for Data Manipulation and Analysis
If you only learn one Python library for Excel analysis, learn Pandas first. Pandas is the foundation for almost every advanced Excel-related task in Python. It turns Excel data into powerful DataFrames for cleaning, transforming, filtering, grouping, merging, aggregating, and exploring large datasets efficiently.
Key Strengths for Excel Pros:
- Read and write Excel files natively with pd.read_excel() and df.to_excel()
- Handle messy data: remove duplicates, fill missing values, and standardize formats
- Perform advanced grouping and aggregation with logic that goes beyond PivotTables
- Merge or join multiple sheets or files
- Generate statistical summaries with df.describe()
- Run a few lines of code and get the same result every time
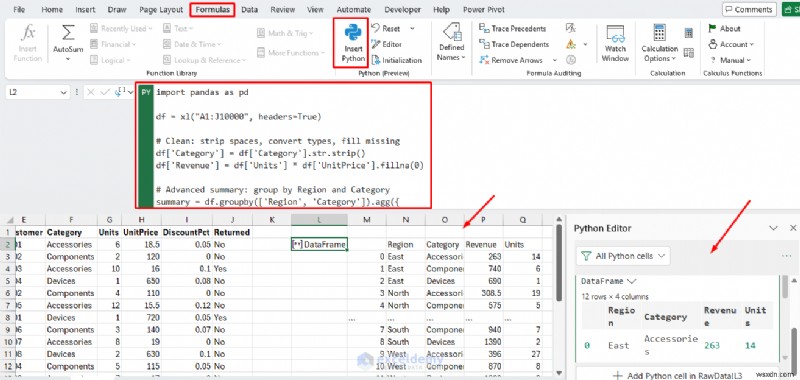
Example: Cleaning Messy Data
A common Excel headache is receiving data with mixed types, missing values, and inconsistent formatting. With Pandas, you can fix everything in one repeatable script.
Python in Excel:
import pandas as pd
df = xl("A1:J10000", headers=True)
# Clean: strip spaces, convert types, fill missing
df['Category'] = df['Category'].str.strip()
df['Revenue'] = df['Units'] * df['UnitPrice'].fillna(0)
# Advanced summary: group by Region and Category
summary = df.groupby(['Region', 'Category']).agg({
'Revenue': 'sum',
'Units': 'sum'
}).reset_index()
summary
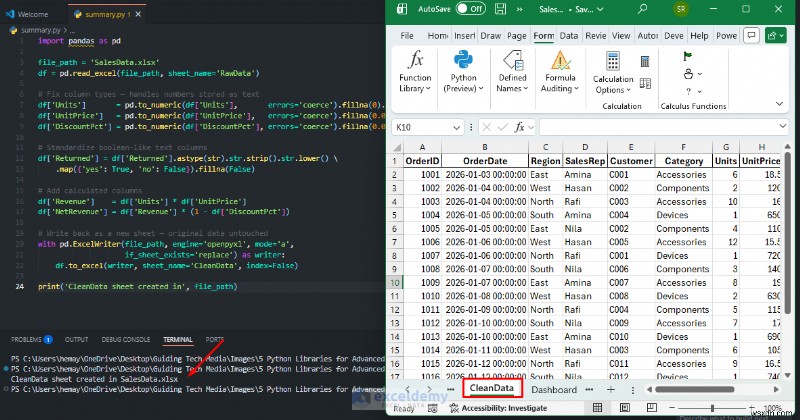
Python in VS Code:
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='RawData')
# Fix column types — handles numbers stored as text
df['Units'] = pd.to_numeric(df['Units'], errors='coerce').fillna(0).astype(int)
df['UnitPrice'] = pd.to_numeric(df['UnitPrice'], errors='coerce').fillna(0.0)
df['DiscountPct'] = pd.to_numeric(df['DiscountPct'], errors='coerce').fillna(0.0)
# Standardize boolean-like text columns
df['Returned'] = df['Returned'].astype(str).str.strip().str.lower() \
.map({'yes': True, 'no': False}).fillna(False)
# Add calculated columns
df['Revenue'] = df['Units'] * df['UnitPrice']
df['NetRevenue'] = df['Revenue'] * (1 - df['DiscountPct'])
# Write back as a new sheet — original data untouched
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
df.to_excel(writer, sheet_name='CleanData', index=False)
print('CleanData sheet created in', file_path)
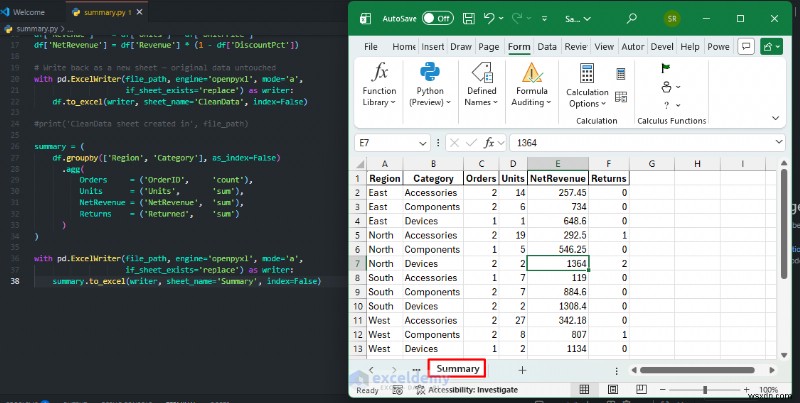
Automating Summary Reports
Replace manual PivotTables with a Pandas groupby workflow that runs in seconds and exports a ready-to-share sheet every time your data updates:
summary = (
df.groupby(['Region', 'Category'], as_index=False)
.agg(
Orders = ('OrderID', 'count'),
Units = ('Units', 'sum'),
NetRevenue = ('NetRevenue', 'sum'),
Returns = ('Returned', 'sum')
)
)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
summary.to_excel(writer, sheet_name='Summary', index=False)
When to Use: You get PivotTable-style output, but the cleanup and logic happen in the same workflow. That means fewer broken reports and less manual intervention. Power users rely on Pandas to handle datasets that are too large or too complex for native Excel, especially when a dataset exceeds a few thousand rows, when you need to repeat a cleaning or summarization step, or when you need to merge data from multiple sources automatically.
2. OpenPyXL – Advanced Excel File Manipulation and Native Formatting
While Pandas handles data, OpenPyXL excels at fine-grained control over .xlsx files: formatting cells, adding charts, tables, styles, formulas, and images without losing Excel-native features. It lets you work directly with .xlsx files, so your Python workflow can produce Excel-ready output instead of raw analysis alone.
Key Strengths for Excel Pros:
- Create and modify workbooks programmatically
- Export cleaned tables into new sheets
- Add professional charts directly in Excel format that update automatically
- Replace old report tabs automatically
- Apply conditional formatting, borders, fonts, and styles to specific cells
- Inject Excel formulas such as =SUM() or =VLOOKUP() into cells
- Protect sheets, freeze panes, and set column widths programmatically
- Build workbook-based deliverables for non-Python users
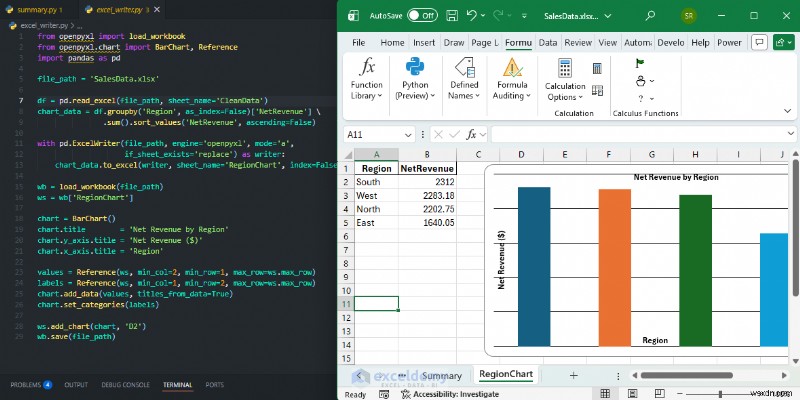
Example: Adding a Native Chart to Your Workbook
After generating clean data with Pandas, use openpyxl to add a professional bar chart without opening Excel manually.
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='CleanData')
chart_data = df.groupby('Region', as_index=False)['NetRevenue'] \
.sum().sort_values('NetRevenue', ascending=False)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
chart_data.to_excel(writer, sheet_name='RegionChart', index=False)
wb = load_workbook(file_path)
ws = wb['RegionChart']
chart = BarChart()
chart.title = 'Net Revenue by Region'
chart.y_axis.title = 'Net Revenue ($)'
chart.x_axis.title = 'Region'
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, 'D2')
wb.save(file_path)
When to Use: Pandas helps you analyze data. openpyxl helps you deliver it. Use OpenPyXL when you need pixel-perfect Excel outputs such as reports and dashboards that look hand-crafted, and when the result needs to live in an .xlsx file with native Excel charts and formatting that colleagues can continue to edit.
3. Matplotlib – Powerful Visualization Beyond Excel Charts
Excel charts are convenient, but Matplotlib gives analysts much more control. Matplotlib is the go-to library for creating static, publication-quality plots. It is highly customizable and integrates well with Pandas for quick exploratory analysis.
Key Strengths for Excel Pros:
- Create advanced plots such as heatmaps, scatter plots with trendlines, box plots, histograms, and 3D charts
- Gain more control over fonts, colors, gridlines, tick marks, and legends
- Build multi-panel subplot layouts that show several charts at once
- Export to images, PDF, or SVG, or embed visuals back into Excel with OpenPyXL
- Annotate data points with custom labels and arrows
Example: Creating a Multi-Panel Sales Dashboard
Let’s create a two-panel chart: a monthly revenue trend on the left and a category breakdown on the right. Then we will save it as a high-resolution image, ready for any report.
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
df['Month'] = pd.to_datetime(df['OrderDate']).dt.to_period('M')
monthly = df.groupby('Month')['NetRevenue'].sum()
cat_rev = df.groupby('Category')['NetRevenue'].sum().sort_values(ascending=True)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
fig.suptitle('Sales Performance Dashboard', fontsize=16, fontweight='bold')
# Left panel — monthly revenue line chart
ax1.plot(list(monthly.index.astype(str)), monthly.values,
marker='o', color='#1E5FAD', linewidth=2)
ax1.set_title('Monthly Net Revenue')
ax1.set_xlabel('Month')
ax1.set_ylabel('Revenue ($)')
ax1.yaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
ax1.tick_params(axis='x', rotation=45)
ax1.grid(axis='y', linestyle='--', alpha=0.5)
# Right panel — revenue by category horizontal bar chart
ax2.barh(cat_rev.index, cat_rev.values, color='#217346')
ax2.set_title('Revenue by Category')
ax2.set_xlabel('Revenue ($)')
ax2.xaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
plt.tight_layout()
plt.savefig('sales_dashboard.png', dpi=150, bbox_inches='tight')
print('Dashboard saved as sales_dashboard.png')
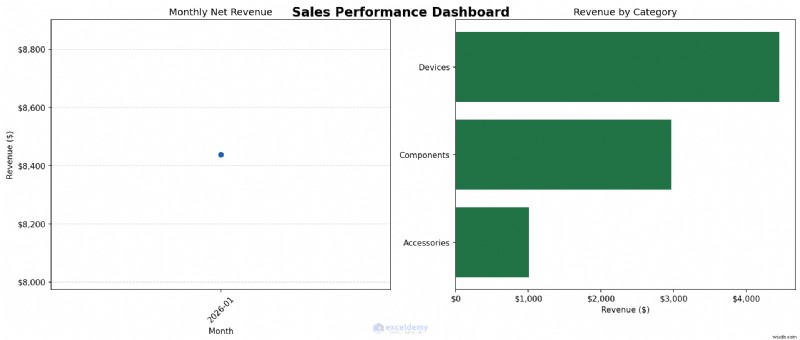
When to Use: Use Python to produce the analysis chart first. Then decide whether the chart should remain a Python output or whether the summarized data should be returned to Excel for final dashboard formatting. Use Matplotlib when you need charts for reports or presentations, or when you need to produce the same chart repeatedly from updated data with consistent styling.
4. Seaborn – Statistical Data Visualization
Seaborn builds on Matplotlib and focuses on statistical visualization. It simplifies the creation of visually appealing charts that highlight patterns and correlations. Where Matplotlib may require dozens of lines for a polished chart, Seaborn can often achieve a similar result in one or two lines with attractive default styling. It excels at revealing distributions, correlations, and patterns hidden in your data.
Key Strengths for Excel Pros:
- Create statistical charts quickly
- Work well for exploratory data analysis
- Build correlation heatmaps to see how columns relate to one another
- Create distribution plots with density curves built in
- Use box plots and violin plots to compare groups visually
- Create pair plots for an automatic scatterplot matrix across numeric columns
- Generate regression plots with confidence intervals in a single line
Example: Creating a Correlation Heatmap
Find hidden patterns in your Excel data: which variables move together? A heatmap can answer this quickly and goes well beyond what Excel’s built-in tools typically provide.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
correlation = df.select_dtypes(include='number').corr()
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation,
annot=True, # show correlation values in each cell
fmt='.2f',
cmap='coolwarm', # red = positive, blue = negative
center=0,
square=True,
linewidths=0.5
)
plt.title('Correlation Matrix — Sales Variables', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('correlation_heatmap.png', dpi=150)
print('Heatmap saved!')
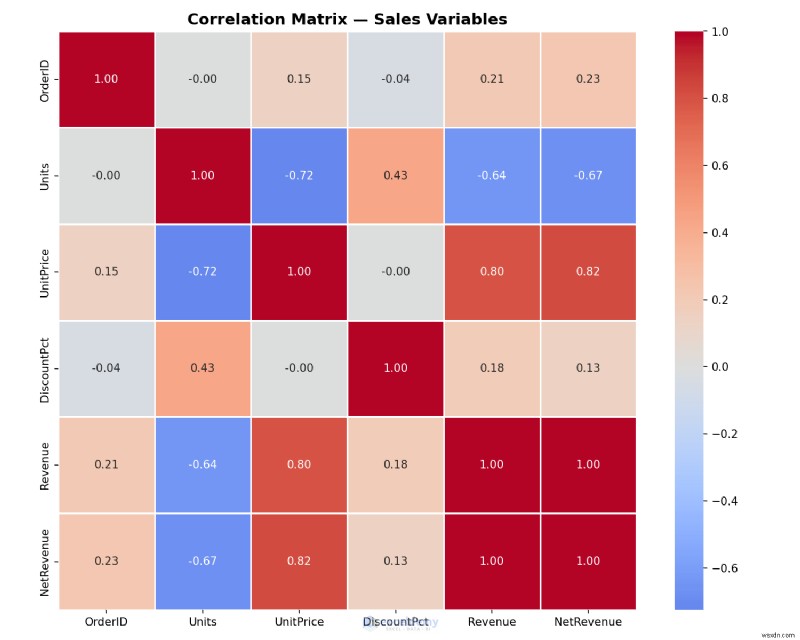
Example: Creating a Box Plot in One Line
Compare revenue distributions across regions to spot outliers instantly.
plt.figure(figsize=(10, 6))
sns.boxplot(data=df, x='Region', y='NetRevenue', hue='Region', palette='Set2', legend=False)
plt.title('Revenue Distribution by Region')
plt.ylabel('Net Revenue ($)')
plt.tight_layout()
plt.savefig('region_boxplot.png', dpi=150)
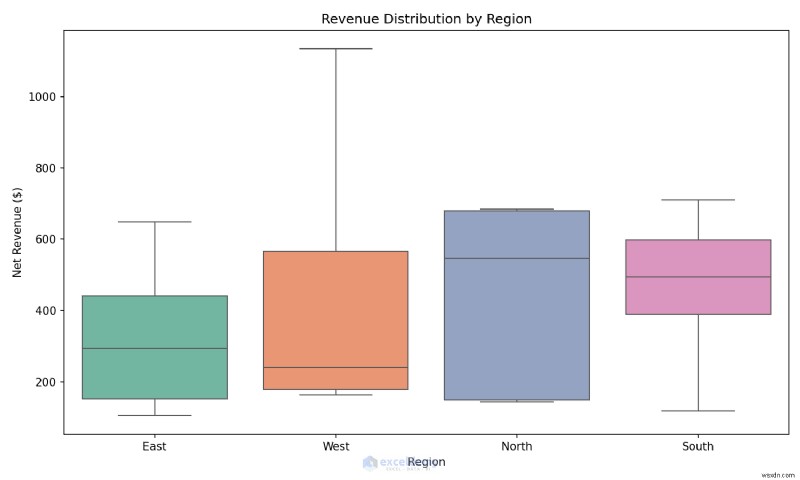
When to Use: Use Seaborn during exploratory analysis when you want to quickly understand distributions, outliers, and relationships before building formal reports.
5. Scikit-learn – Machine Learning Directly on Excel Data
This is the library that moves you from reporting to decision support. Scikit-learn brings professional machine learning to your Excel workflow. It enables predictive analytics for Excel users, including regression, classification, clustering, and forecasting that native Excel cannot handle easily. Rather than only describing what happened in your data, it helps you predict what may happen next, from forecasting sales to classifying customers to detecting anomalies.
Key Strengths for Excel Pros:
- Linear and logistic regression to predict numeric outcomes or categories such as churn risk or sales forecasts
- Decision trees and random forests for interpretable predictions
- K-means clustering to group similar records automatically
- Train-test splitting and cross-validation to measure model accuracy
- Feature scaling, encoding, and preprocessing pipelines
- Return predictions to Excel for filtering and sorting
Example: Predicting Net Revenue
Train a model on your historical sales data, then use it to predict revenue for new orders, which is an analysis Excel cannot perform natively.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import LabelEncoder
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
# Encode categorical columns as numbers
for col in ['Region', 'Category', 'SalesRep']:
if col in df.columns:
df[col] = LabelEncoder().fit_transform(df[col].astype(str))
X = df[['Units', 'UnitPrice', 'DiscountPct', 'Region', 'Category']]
y = df['NetRevenue']
# Split: 80% train, 20% test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train a Random Forest model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate accuracy
predictions = model.predict(X_test)
print(f'Mean Absolute Error: ${mean_absolute_error(y_test, predictions):,.2f}')
print(f'R² Score: {r2_score(y_test, predictions):.4f}')
# Export predictions back to Excel
results = X_test.copy()
results['Actual'] = y_test.values
results['Predicted'] = predictions
results.to_excel('predictions.xlsx', index=False)
print('Predictions exported to predictions.xlsx')
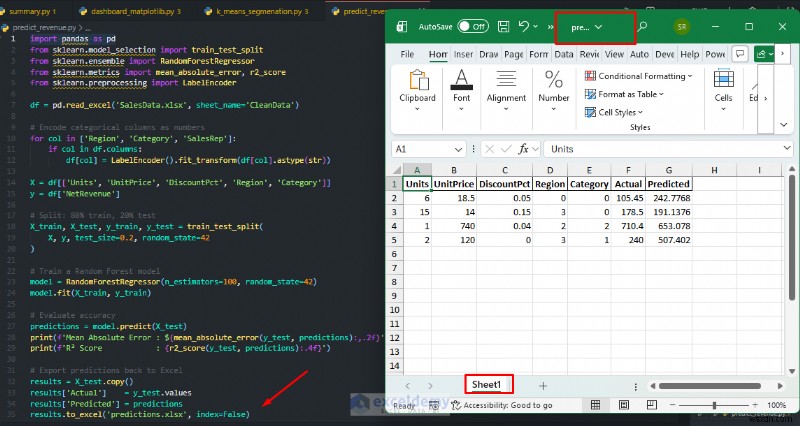
K-Means Customer Segmentation:
Automatically segment customers into groups based on purchasing behavior, with no manual criteria required.
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
customer = df.groupby('Customer').agg(
TotalOrders = ('OrderID', 'count'),
TotalRevenue = ('NetRevenue', 'sum'),
AvgDiscount = ('DiscountPct', 'mean')
).reset_index()
X_scaled = StandardScaler().fit_transform(
customer[['TotalOrders', 'TotalRevenue', 'AvgDiscount']]
)
customer['Segment'] = KMeans(n_clusters=3, random_state=42, n_init=10) \
.fit_predict(X_scaled)
customer.to_excel('customer_segments.xlsx', index=False)
print('Segmentation complete! See customer_segments.xlsx')
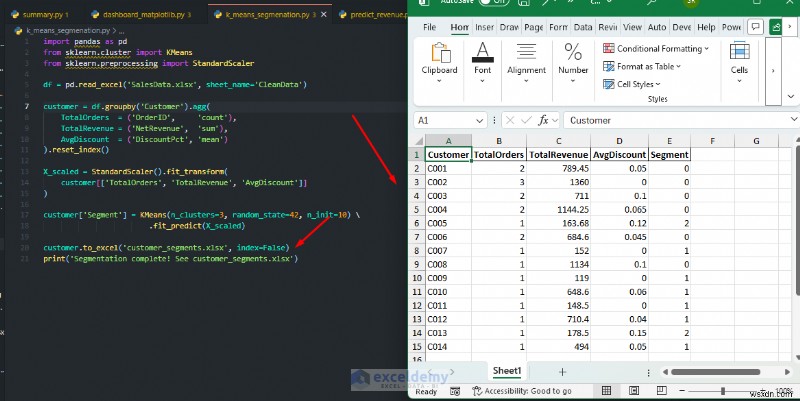
When to Use: You can write predictions back into a worksheet, then let Excel users filter, sort, chart, or combine the results with formulas and conditional formatting. This allows professionals to add machine learning insights directly back into spreadsheets. Use Scikit-learn when you need to forecast future values, classify records, or discover natural groupings that PivotTables cannot reveal.
Bonus: Xlwings – Bi-Directional Automation and Live Excel Integration
The xlwings library runs an Excel instance in real time. It bridges Python and Excel, enabling true automation. While openpyxl reads and writes static files, xlwings can open Excel, manipulate it live, read values back into Python, trigger Python functions from Excel buttons, and build full UDFs (user-defined functions) that appear in cells. It is a modern alternative to many VBA-based workflows.
Key Strengths for Excel Pros:
- Control a live Excel session: open, read, write, and close workbooks programmatically
- Write Python functions callable directly from Excel cells as UDFs
- Automate repetitive tasks such as refreshing data and generating reports
- Push Pandas DataFrames and Matplotlib charts directly into named ranges
- Run Python scripts triggered by Excel buttons
- Work on both Windows and macOS
- Serve as a strong alternative or complement to Python in Excel for desktop workflows
You can use xlwings when you need live, two-way interaction with Excel, when replacing VBA macros, when building interactive dashboards, or when allowing non-technical colleagues to trigger Python analyses with a button click.
Choosing The Best Library Stack For Different Excel Pros
Not every analyst needs all five libraries at once. A practical way to adopt them is by role.
- For Reporting Analysts: This combination lets you clean data, create summaries, generate charts, and export polished workbook outputs.
- Pandas
- Matplotlib
- Openpyxl
- For Finance and Operations Analysts: This stack works well for modeling, KPI calculations, allocations, and repeatable monthly reporting.
- Pandas
- Seaborn
- Openpyxl
- For Advanced Analytics Teams: This combination gives you the full pipeline from data preparation to predictive scoring to workbook delivery.
- Pandas
- Matplotlib
- Scikit-learn
- Openpyxl
- Seaborn
Final Thoughts
These are five Python libraries for advanced Excel data analysis that every pro should use. Master these tools, and you can transform Excel from a simple spreadsheet application into a more capable analytics platform. A sensible learning path is to start with Pandas, then add openpyxl, then learn Matplotlib and Seaborn together, and tackle Scikit-learn after that. Each library works with the same .xlsx files you already use. Start exploring them to become a more capable data analyst.
Get FREE Advanced Excel Exercises with Solutions!